| Author |
Message |
|---|
JohanssonSend message
Joined: 30 Oct 21
Posts: 2
Credit: 89,434,925
RAC: 176,452
Level

Scientific publications
 |
|
Hi
Usually my computer gets a WU done in about a couple of days... But some time ago I found out that it had been running one for several days and was not going anywhere, it was apparently just stopped at 2%. I checked, that GPU was not doing anything, MSI Afterburner was reporting the kinds of low-ish clock-rates, temps and such as it typically would be without any GPU load, other than managing the usual windows desktop.
I did take a look at forums, didn't see anything obvious about similar problems. So I thought, maybe it is just one off thing, and aborted it. But now, I have a WU just like it. Stuck at 2%, exactly 2%. And GPU is idling.
Application : Python apps for GPU hosts 4.03 (cuda 1131)
Name : e16a6-ABOU_rerun_agents_23-0-1-RND5671 |
|
|
JohanssonSend message
Joined: 30 Oct 21
Posts: 2
Credit: 89,434,925
RAC: 176,452
Level
Scientific publications
|
|
Ok, so I have done some trouble shooting... And it seems the problem might be in the fact that my computer didn't have enough memory.
I increased the allowed size of cache files, and it seems to be doing something now.
Obviously would be better, if I could put more RAM, but for now this seems to have solved the problem. |
|
|
MichaelSend message
Joined: 17 Sep 10
Posts: 1
Credit: 175,780,604
RAC: 129,330
Level

Scientific publications
|
|
I have the same issue, progress stuck at 2% with 62 days remaining. I have 32GB of RAM, so I don't thing that is the issue. All I can do is abort the task and hope I get a better job next time. I have 6GB of on a nVidia 1660Super |
|
|
jjchSend message
Joined: 10 Nov 13
Posts: 101
Credit: 15,569,300,388
RAC: 3,786,488
Level

Scientific publications
 contribution to Doerr et al. JCTC 2014")  contribution to Stanley et al, Nat Commun 2014")  contribution to Lauro et al., JCIM 2014")  contribution to Ferruz et al., Sci Rep 2016") |
|
Two of my Windows 10 workstations are experiencing this since yesterday. They both have 8GB memory but that doesn't seem to be maxing out. The CPU's are fairly busy running SiDock but suspending those doesn't seem to make a difference.
Are the Python apps for GPU hosts 4.03 (cuda1131) broken on Windows hosts?
Do I need to reserve more CPU than the default 0.988 for these tasks? They are set at 1 GPU. Is there some other software or update needed?
|
|
|
|
|
|
jjch asked: Do I need to reserve more CPU than the default 0.988 for these tasks?
Yes. Try running the task by itself to see how many CPUs it uses. On my 8 core 16 thread machine, it will use about 10 threads. On my 6 core 12 thread machine, it will use about 8 threads. |
|
|
Keith Myers  Send message Send message
Joined: 13 Dec 17
Posts: 1340
Credit: 7,653,273,724
RAC: 13,371,735
Level

Scientific publications
 contribution to Martinez-Rosell et al, JCIM 2020")  contribution to Rodriguez-Espigares et al., Nat Meth 2020")  contribution to Cossu et al, JCIM 2020") |
|
On 32 or 48 thread hosts, I reserve 3 cpu cores for the Python app via an app_config.xml statement. Should reserve 5 cores but I don't want to take away too many cpu threads from my cpu project tasks.
Don't have any issues doing this. But all hosts are Linux based. |
|
|
|
|
Two of my Windows 10 workstations are experiencing this since yesterday. They both have 8GB memory but that doesn't seem to be maxing out. The CPU's are fairly busy running SiDock but suspending those doesn't seem to make a difference.
At the beginning of Python GPU App development, when there was only Linux version, I found system memory to be a limiting factor for my hosts.
I Published then some tips at thread Making Python GPU tasks to succeed - User side
Taken from there:
-1) System RAM must be at least 16 GB for each ABOU Python GPU task in execution.
If your system has one only GPU, then 16 GB of system RAM should be enough.
If the system has two GPUs installed and two ABOU Python GPU tasks are being concurrently executed, then the minimum system RAM should be 32 GB... And so on.
If you are thinking about upgrading your system RAM to meet these requirements (as I had to do for my hosts), I published a how-to at post Upgrading system RAM, It's easy |
|
|
jjchSend message
Joined: 10 Nov 13
Posts: 101
Credit: 15,569,300,388
RAC: 3,786,488
Level
Scientific publications
|
|
I'm not entirely convinced that what's happening here is directly related to a HW resources issue.
GPUgrid is starting several Python apps but they are just stalling and not going anywhere. It seems like it is missing something that it needs to run or it is being blocked. Is there a log file that would show problems like this?
Is there anything else that I need to install or configure for the Python apps on a Windows system? Is there a known incompatibility with something else that I may be running?
I also have several Windows 2012 servers that failing Python apps. Most of these are fairly robust servers so I wouldn't think they have a resource issue either.
The error messages look something like this:
...
21:08:15 (512): .\7za.exe exited; CPU time 40.859375
21:08:15 (512): wrapper: running python.exe (run.py)
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'NewConnectionError('<pip._vendor.urllib3.connection.HTTPSConnection object at 0x000000B729119640>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed')': /simple/pytorchrl/
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'NewConnectionError('<pip._vendor.urllib3.connection.HTTPSConnection object at 0x000000B729119790>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed')': /simple/pytorchrl/
WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'NewConnectionError('<pip._vendor.urllib3.connection.HTTPSConnection object at 0x000000B7291199D0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed')': /simple/pytorchrl/
Starting!!
Windows fix!!
Traceback (most recent call last):
File "run.py", line 467, in <module>
from pytorchrl.envs.atari import atari_train_env_factory
File "C:\ProgramData\BOINC\slots\58\lib\site-packages\pytorchrl\envs\atari\__init__.py", line 1, in <module>
from pytorchrl.envs.atari.atari_env_factory import atari_train_env_factory, atari_test_env_factory
File "C:\ProgramData\BOINC\slots\58\lib\site-packages\pytorchrl\envs\atari\atari_env_factory.py", line 1, in <module>
from pytorchrl.envs.atari.wrappers import wrap_deepmind, make_atari, MontezumaVisitedRoomEnv,\
File "C:\ProgramData\BOINC\slots\58\lib\site-packages\pytorchrl\envs\atari\wrappers.py", line 8, in <module>
import cv2
ImportError: DLL load failed while importing cv2: The specified module could not be found.
21:33:04 (512): python.exe exited; CPU time 16.078125
21:33:04 (512): app exit status: 0x1
21:33:04 (512): called boinc_finish(195)
...
https://www.gpugrid.net/result.php?resultid=32896395
Here is another one that doesn't have the https error
https://www.gpugrid.net/result.php?resultid=32896228
The tasks I see completing successfully are mostly on Linux but there are a few Windows 10 and 11 systems.
Does anyone have a known working Windows 10 or server 2012 system that is processing these tasks successfully and knows something they did to get it to work?
Any thoughts would be appreciated. |
|
|
Keith Myers Send message
Joined: 13 Dec 17
Posts: 1340
Credit: 7,653,273,724
RAC: 13,371,735
Level
Scientific publications
|
|
You are having difficulty downloading the pytorch libraries that the task needs to set itself up correctly.
Look into openssl, curl and nss3 security issues on Windows.
There have been many recent security updates for CVE vulnerabilities patched in the past couple of weeks.
Maybe Windows is a bit behind on updating. |
|
|
jjchSend message
Joined: 10 Nov 13
Posts: 101
Credit: 15,569,300,388
RAC: 3,786,488
Level
Scientific publications
|
|
Thanks Keith,
There may be a couple different things happening.
On the Windows 10 workstations I found an error in the stderr output related to the Windows paging file being too small.
An example from one host:
OSError: [WinError 1455] The paging file is too small for this operation to complete. Error loading "C:\ProgramData\BOINC\slots\13\lib\site-packages\torch\lib\cudnn_cnn_infer64_8.dll" or one of its dependencies.
https://www.gpugrid.net/result.php?resultid=32896411
Another host fails with a different file:
OSError: [WinError 1455] The paging file is too small for this operation to complete. Error loading "C:\Test\BOINC\Program Data\slots\13\lib\site-packages\torch\lib\shm.dll" or one of its dependencies.
https://www.gpugrid.net/result.php?resultid=32896392
It seems to be coming from the Windows OS side so I will need to look into that and figure out if I can change it. Haven't ever adjusted it on Win 10 systems.
Not sure if this could be coming from a BOINC setting.
The Win 2012 servers might actually have a different issue that could be more likely related to what you noted below.
|
|
|
Keith Myers Send message
Joined: 13 Dec 17
Posts: 1340
Credit: 7,653,273,724
RAC: 13,371,735
Level
Scientific publications
|
|
That could definitely be adjusted in Windows 7. Assume the same for Windows 10.
Haven't run Windows in so long to not remember how to do that exactly.
So Google gives this.
https://computerinfobits.com/adjust-page-file-windows-10/ |
|
|
jjchSend message
Joined: 10 Nov 13
Posts: 101
Credit: 15,569,300,388
RAC: 3,786,488
Level
Scientific publications
|
|
Keith,
I found the Paging file setting in Windows 10 similar to what you noted below.
It's set for Automatic with a Currently allocated size of 24576 MB. I'm thinking that's already pretty big but I could try manually setting it to something a bit more than that. Maybe 32Gb?
I would hope that Windows would allocate whatever is called for but maybe it's maxing out and the python app needs more?
Right now with only GPUgrid running I can see the physical memory is using about 5018MB out of 8Gb and there is 3069MB available.
While it's sitting there happily not doing anything I have 20 Python.exe images and one has about 2GB Committed and the rest are 1GB.
Also, one python.exe has 13 CPU threads and the rest are 3 with 0 CPU time.
Does anyone with a Windows 10/11 system know what size paging file works? It might depend on what physical memory is available so that would be helpful to know as well.
Is there any real-time BOINC/GPUgrid log that would show what the applications are currently doing or where they are stalled? I'm only seeing the stderr after the job fails or is aborted.
|
|
|
Keith Myers Send message
Joined: 13 Dec 17
Posts: 1340
Credit: 7,653,273,724
RAC: 13,371,735
Level
Scientific publications
|
|
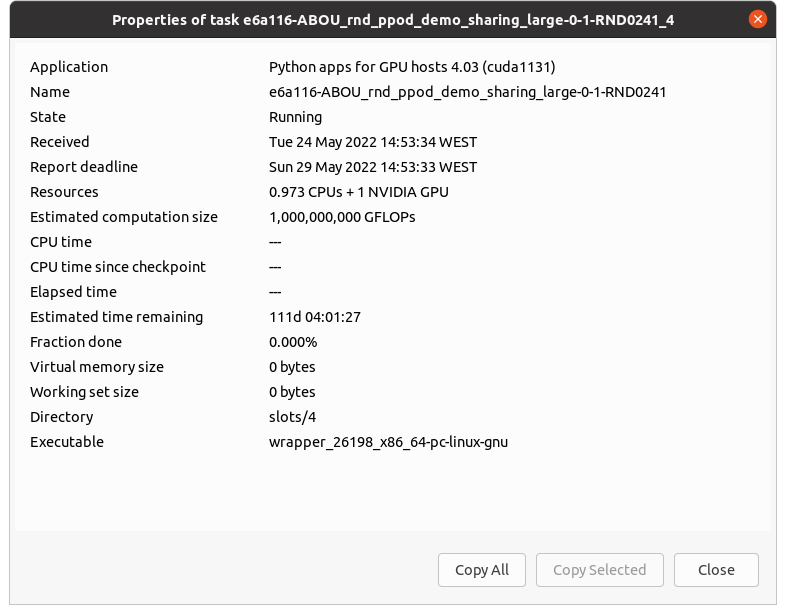
You can always click on the running GPUGrid task and use the Properties selection from the left hand menu in the Manager.
That will show the amount of virtual memory the task is using. My current Python task shows a little over 17GB of Virtual Memory in use with a Working Memory size of a little over 5GB.
In Windows I'm sure you can also see how much memory a Task is using via the Task Manager and the Process Explorer.
To see what the task is doing you can look in the properties menu and see what slot the task is running in and then look at the stderr.txt file in that Slot to see where the current state of the computation is.
You could look and see if the task is stumbling in progress and find some clues there.
I guess the tasks automatically size themselves according to how much system memory the host has available. I didn't think they would run in only 8GB.
My task is using about 15GB of physical memory currently along with the 17GB of virtual memory. My hosts have either 32GB or 128GB of memory. All run Ubuntu Linux. |
|
|
|
|
|
If I restart the PC, the task also restarts and starts at "zero" even if the task had already been running for several hours |
|
|
jjchSend message
Joined: 10 Nov 13
Posts: 101
Credit: 15,569,300,388
RAC: 3,786,488
Level
Scientific publications
|
|
It's not reaching a checkpoint to save the work but I'm not actually sure what that is for the Python apps.
You should avoid restarting your PC if possible for these extended runtime tasks.
|
|
|
jjchSend message
Joined: 10 Nov 13
Posts: 101
Credit: 15,569,300,388
RAC: 3,786,488
Level
Scientific publications
|
|
I have another task that is stalled at 2% even after I increased the paging file to a max of 32768 MB. It's currently allocated 31499 MB which is around 1GB less. I'm thinking I can keep trying to increase this and see if it helps.
I found 28 python.exe processes running now. The first one shows 2,538,676 KB which is very close to the 2.42 GB that the task properties shows for Virtual memory size. It does not show the rest of the between 1,137,988 and 1,139,116 KB Committed for each of the remaining 27 processes.
Looking at the stderr in that slot I can see the paging file is too small error. That helps to see it's still suffering from the same problem. Unfortunately I think that when a task chokes it's done and I'm not seeing a way to save it.
We are not getting many Windows tasks so I have to wait for another to come by.
The main question is how far can these python apps go? What is the maximum number of processes and memory needed for one to actually start? |
|
|
Keith Myers Send message
Joined: 13 Dec 17
Posts: 1340
Credit: 7,653,273,724
RAC: 13,371,735
Level
Scientific publications
|
|
If you examine the properties of the task, it will show the last checkpoint that the task has written.
Also in the slot the task occupies, it will also have the checkpoint files.
The nice thing about the Python tasks compared to the acemd3/4 tasks is that they will restart from checkpoint on a different device without error.
You can stop BOINC and restart it and the Python GPUGrid task will restart from 1% and then catch up to the last checkpoint after a few minutes after it reads the last checkpoint file. |
|
|
|
|
|
I have the same problem.
Then I excluded python tasks, now I only get python tasks that go to 2% and 100+ days to complete and do nothing. |
|
|
Keith Myers Send message
Joined: 13 Dec 17
Posts: 1340
Credit: 7,653,273,724
RAC: 13,371,735
Level
Scientific publications
|
|
As mentioned previously by myself and the developer, the days to complete is wildly inaccurate and can be ignored.
When I see a task first start it has over 1100 days to completion but actually completes in 7-12 hours depending on the cpu and gpu. |
|
|
|
|
|
Under certain circumstances, there are similar problems also in Linux app.
I've reproduced a variant of this thread topic: GPU Idling, progress halted at 0% (no progress at all)
It has happened at two of my Linux hosts when pausing ABOU python GPU tasks before the first checkpoint is taken.
The symptom is: After resuming the task, the progress indication remains eternally at 0.000%, and Elapsed time at "---".
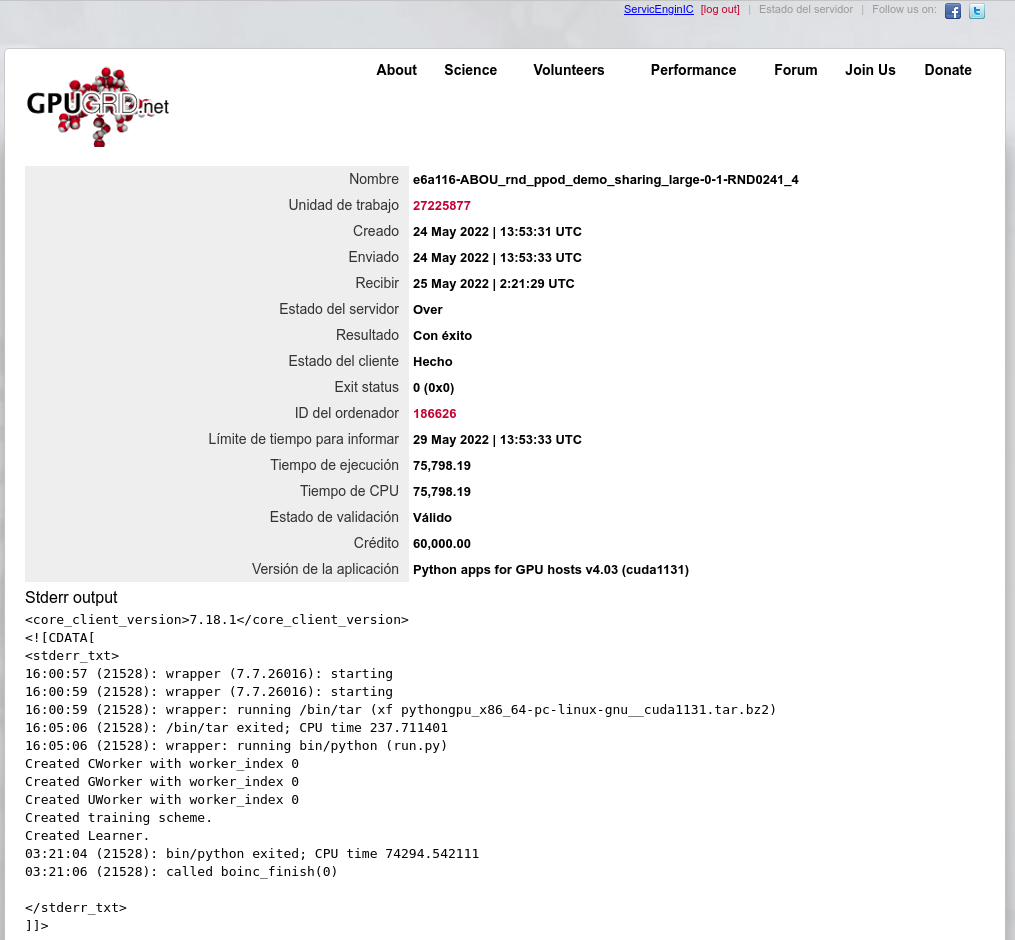
The first time I experienced this, I thought that it was due to a defective task, and I aborted it after more than 8 (wasted) hours had passed. It was at my host #557889
Then I saw that the same WU #27225271 was completed later by another (Windows 10) host.
The second time, it happened at my host #186626, and I documented it.
It happened to task e6a116-ABOU_rnd_ppod_demo_sharing_large-0-1-RND0241_4
When a previous PrimeGrid GPU task finished and I resumed that Gpugrid python task, task Status was marked as "Running", but progress was stuck at 0.000%, and Elapsed time counter did not move at all after several minutes.
I tried to pause the task and restart it again, with the same result: "Running" status, but progress and elapsed time keeping frozen.
Also I noticed that GPU was idling.
This time, I tried an emergency remedy before aborting the task, by stopping activity at BOINC Manager and running the following commands at a Linux Terminal window:
sudo killall boinc
sudo /etc/init.d/boinc-client restart
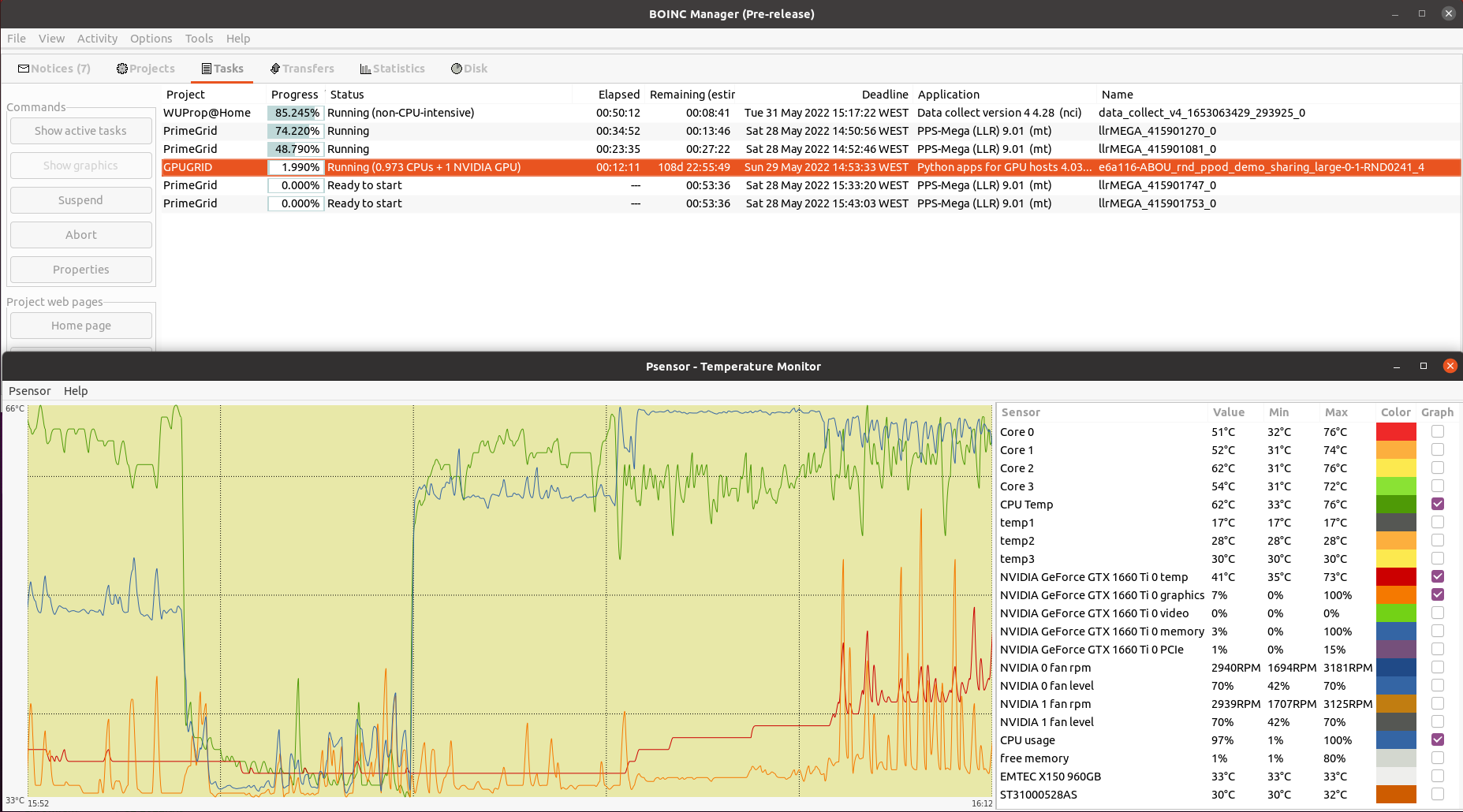
After that, when resuming activity at BOINC Manager, task started to progress normally, and it reached the learning cycle as usual.
Finally, the task ended successfully. |
|
|
Keith Myers Send message
Joined: 13 Dec 17
Posts: 1340
Credit: 7,653,273,724
RAC: 13,371,735
Level
Scientific publications
|
|
I don't think I have ever observed your symptom.
But then I don't use the distro service install of BOINC either.
I use a custom client based on the original Berkeley installer.
So that probably accounts for the difference in observed behavior. |
|
|
 ServicEnginIC
ServicEnginIC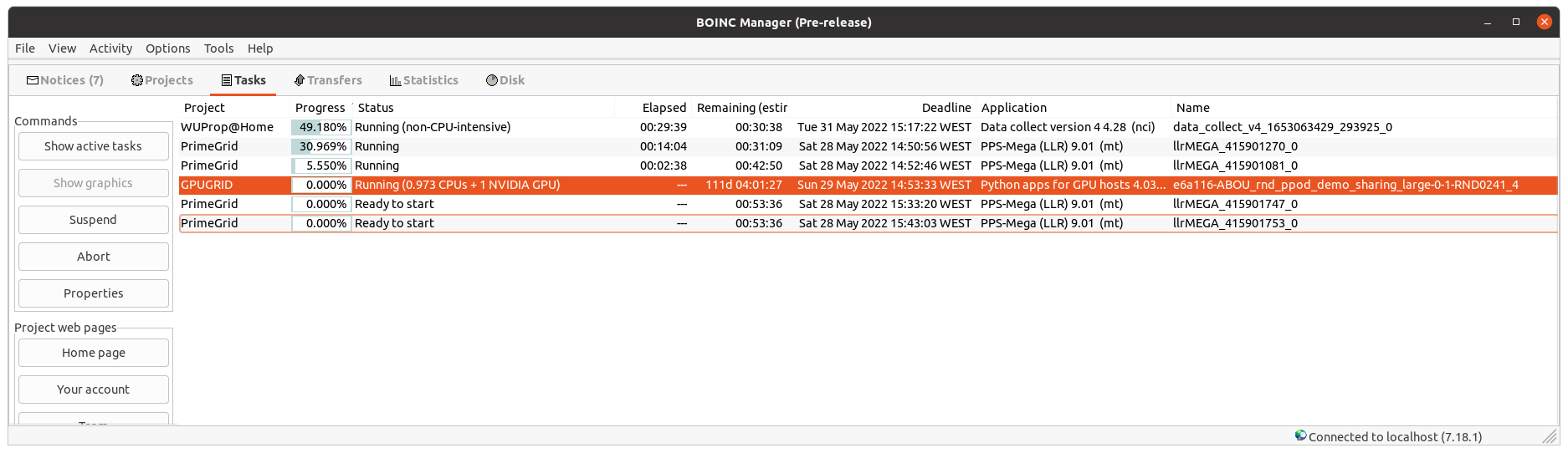{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}